Вернуться к блогу

Hola Amigos! На связи Евгений Шмулевский, PHP-разработчик продуктового агентства Amiga. В этой статье мы разберем, как сделать простую рекомендательную систему. На входе у нас карточка товара, а на выходе — n похожих карточек, определенных на основе характеристик. Ссылка на исходный код проекта здесь.
Мы будем подбирать похожие автомобили, используя датасет с Kaggle. Датасет содержит 11 914 автомобилей, выпущенных с 1990 по 2017 годы. В нем представлены следующие данные:
Для поиска похожих элементов будем использовать pg_vector — расширение PostgreSQL, работающее с эмбеддингами. Если упростить, эмбеддинг — это представление данных в виде вектора (массив float). Эмбеддинги можно использовать для текста, изображений, характеристик товаров и т.д. В нашем случае — для характеристик автомобилей.
Альтернативой pg_vector могут служить полноценные векторные базы данных, например:
Но я решил остановиться на pg_vector, т.к. он позволяет обойтись без установки дополнительного ПО, что удобно, если проект уже использует PostgreSQL.

Далее для получения n близких товаров будем использовать SQL-запрос в pg_vector.
Вот пример простого запроса:
SELECT * FROM items ORDER BY embedding <-> '[3,1,2]' LIMIT 5;
Оператор <-> рассчитывает расстояние между векторами на основе евклидова расстояния (L2). Под [3,1,2] подразумевается векторный эмбеддинг. Ниже на изображении видно разницу.
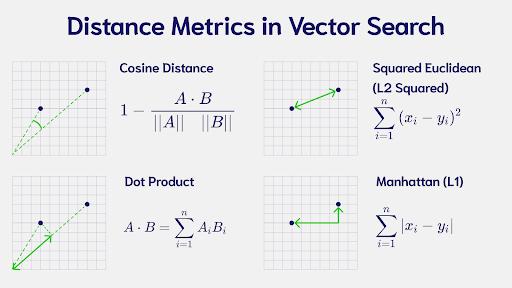
В pg_vector доступны следующие операторы:
<%> — Jaccard distance (для бинарных векторов)
Для установки pg_vector можно использовать готовый Docker-образ:
docker pull pgvector/pgvector:pg16
Или собрать вручную:
FROM postgres:17
RUN apt-get update && apt-get install -y \
build-essential \
git \
postgresql-server-dev-all \
&& rm -rf /var/lib/apt/lists/*
WORKDIR /tmp
RUN git clone https://github.com/pgvector/pgvector.git
WORKDIR /tmp/pgvector
RUN make
RUN make install
Затем активируем расширение для каждой новой БД: CREATE EXTENSION vector;
Для расчета эмбеддингов можно применить 2 стратегии: расчитать самим, либо использовать одну из моделей для расчета эмбеддингов.
Для расчета вручную нужно привести значения характеристик к одному масштабу. Здесь возможно использовать один из вариантов:
Для категорийных данных (те, которые имеют конечное число вариантов) будем использовать one hot encoding. Например, у нас есть характеристика по цвету и возможны варианты: красный, синий и зеленый. Тогда для эмбеддингов у нас получатся значения 001,010 и 100.
Вторая стратегия заключается в использовании языковых моделей для создания эмбеддингов. Например: OpenAI GPT (text-embedding-ada-002), BERT-based модели и др. При такой стратегии все характеристики склеиваются в одну строку и далее пропускаются через модель. Здесь можно также при необходимости включить описание, тогда на поиск будет влиять также сходство в описании товара.
Для нашего примера возьмем MinMax — для этого создадим сервис который будет расчитывать эмбеддинги раз в сутки.
В результате у нас должны получиться эмбеддинги примерно следующего вида (в конце мы заполняем оставшееся значения 0 для получения размерности в 200). Как видно, категориальные значения представляют собой 0 и 1, а числовые нормализованы через MinMax:

Для создания доп. колонки воспользуемся напрямую SQL-запросом в миграции.
DB::statement('ALTER TABLE cars ADD COLUMN embedding vector(200);')
Поддерживаемые типы:
Размерность эмбеддингов определяется суммой всех возможных вариантов для категориальных данных + числовые признаки.
Для нашего примера рассчитаем размерность вектора как сумму всех возможных вариантов для категориальных данных (которые являются справочниками и которые мы намерены использовать в нашей системе). Также можно взять запас исходя из того, что со временем справочники будут пополняться новыми значениями.
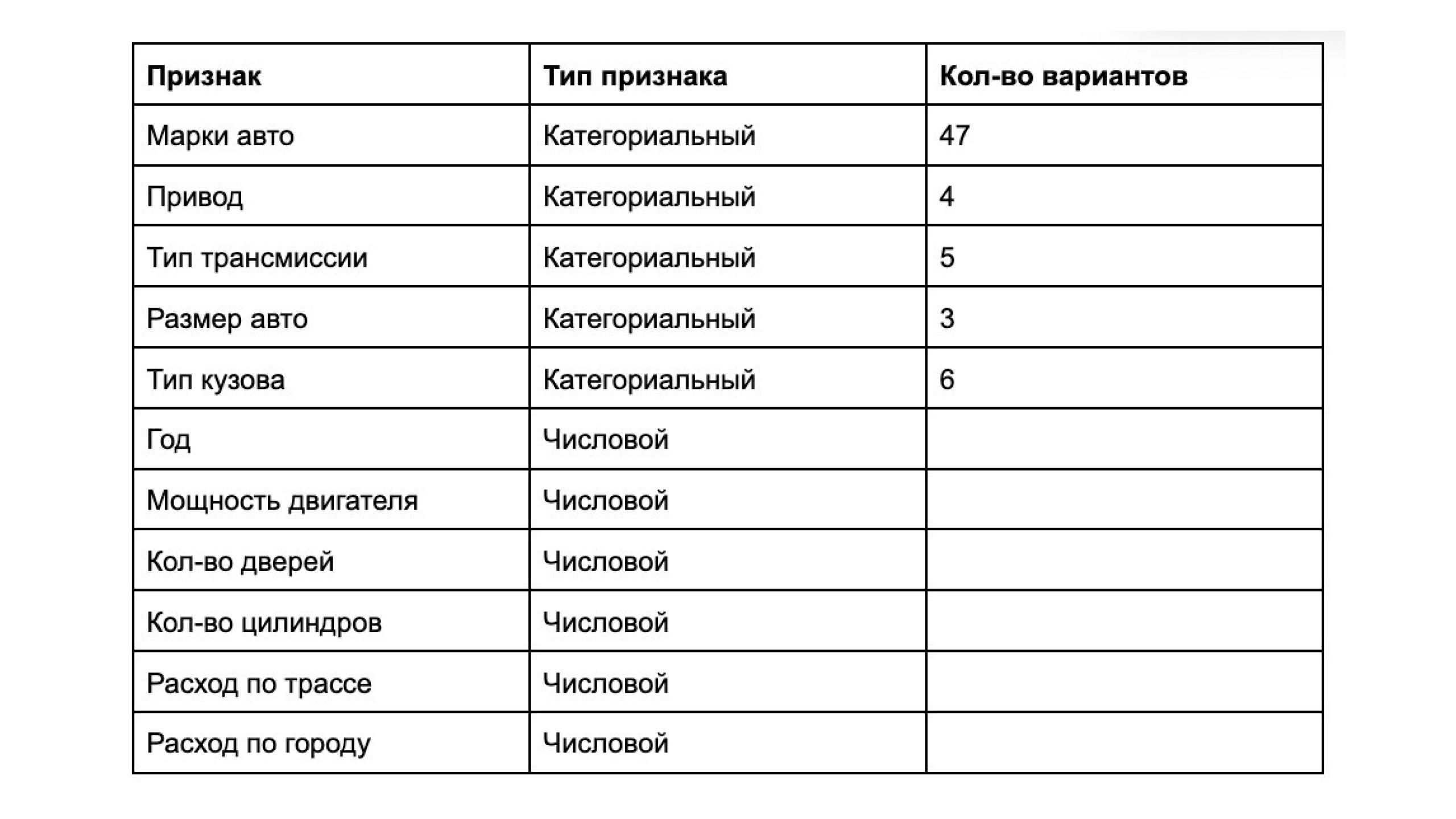
Итого: 71, соответсвено размерность эмбеддинга должна быть минимально 71 + количество не категориальных признаков.
Далее создаем индекс. pg_vector поддерживает два типа индексов:
1. HNSW (медленное создание, быстрая выборка).
2. IVFlat (быстрое создание, медленная выборка).
Пример создания индекса IVFlat:
DB::statement('CREATE INDEX cars_embedding_index ON products USING ivfflat (embedding vector_l2_ops) WITH (lists = 200);');
Параметр lists отвечает за деление векторов на количество, заданное в lists. Выбирать значение рекомендуется как количество записей / 1000. Если записей более 1M, то как квадратный корень.
Пример создания индекса HNSW:
DB::statement('CREATE INDEX cars_embedding_index ON cars USING hnsw (embedding vector_l2_ops) WITH (m = 16, ef_construction = 64);');
Согласно документации, параметр m — максимальное количество связей на слой (16 по умолчанию) и ef_construction — размер динамического списка кандидатов для построения графа (64 по умолчанию).
При создании обоих типов индексов можно указать алгоритм, который будет использоваться при выборке. В данном случае vector_l2_ops означает L2. Также возможно использование:
После создания миграций перейдем к самим запросам. Для получения похожего товара можем использовать запрос такого вида:
SELECT id,
car_mark_id,
car_model_id,
year,
engine_hp,
highway_mpg,
city_mpg,
msrp,
vehicle_style_id,
transmission_type_id,
embedding <-> (
SELECT embedding
FROM cars
WHERE id = 1
) AS distance
FROM cars
ORDER BY distance
LIMIT 10;
В результате получим вот такой список авто:
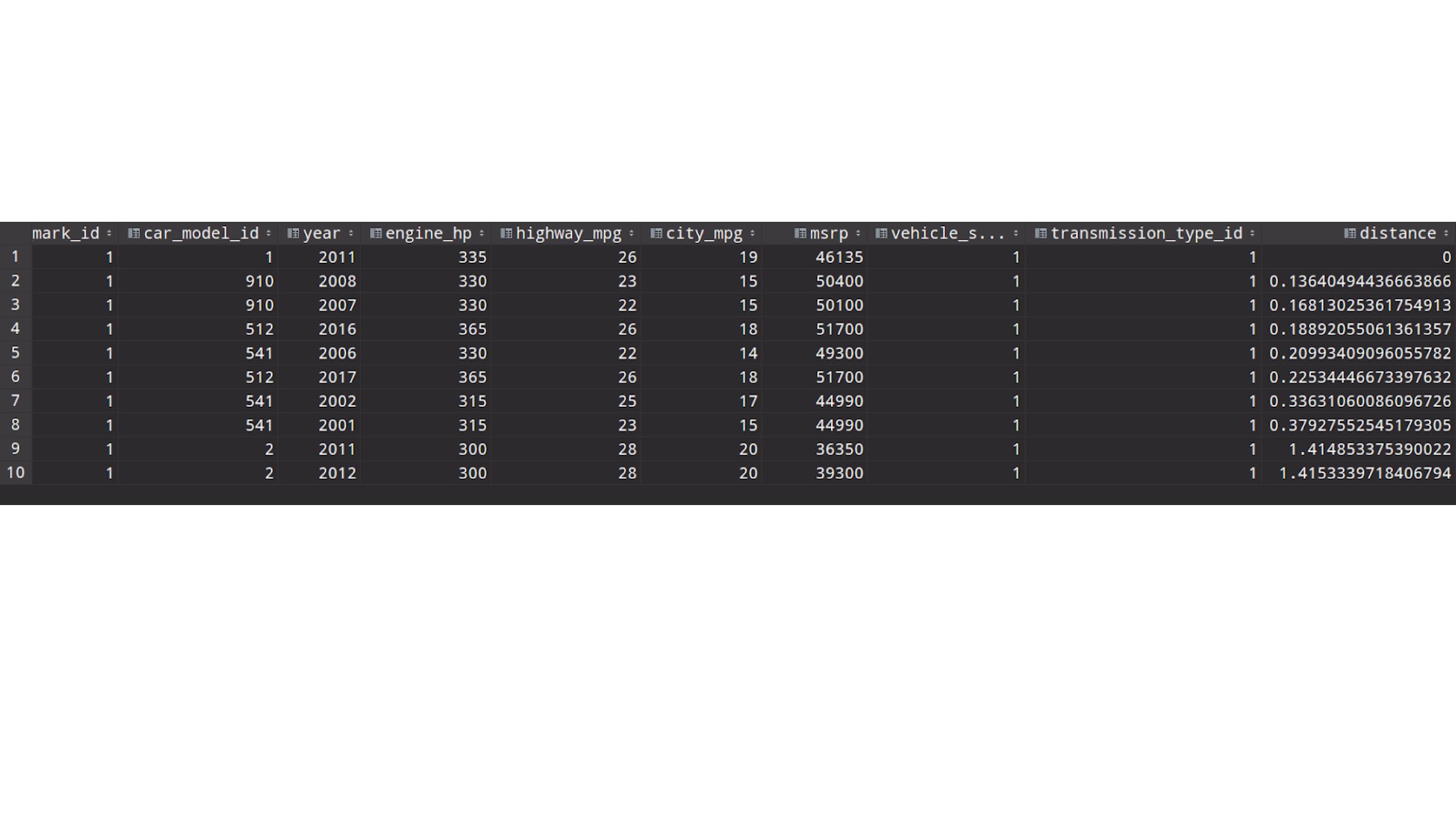
Как видно, наиболее похожими на BMW 1 Series M 2011 г.в. являются авто также марки BMW, но другого модельного ряда.
Далее реализуем веб-интерфейс (в данном случае я использовал Vue3). Ниже представлен скрин. Вверху выведен список авто, а при клике ниже отображается список авто с похожими характеристиками. В колонке dist содержится инфо о близости к исходному авто.
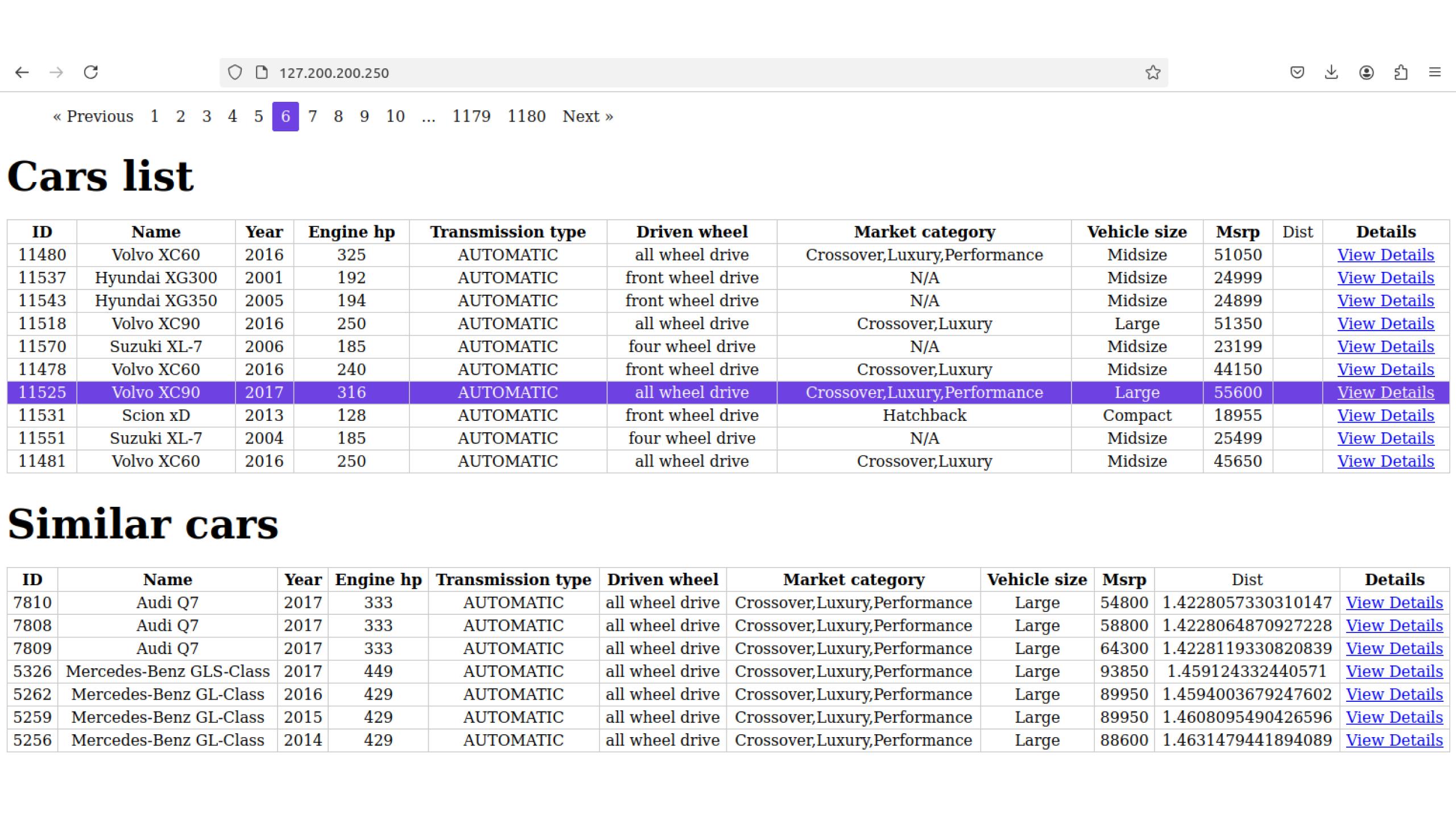
Выборка похожих авто делается через метод репозитория. То есть мы выбираем 10 наиболее близких авто, но другой модели и марки.
Ниже пример части метода:
$car = Car::query()
->select('car_mark_id','car_model_id')
->where('id', '=', $id)
->first();
$builder = Car::query()->select(
'id',
'car_mark_id',
'car_model_id',
'driven_wheel_id',
'transmission_type_id',
'market_category_id',
'vehicle_size_id',
'engine_cylinders',
'highway_mpg',
'vehicle_style_id',
'engine_hp',
'msrp',
'year'
);
$builder->selectRaw("embedding <-> (SELECT embedding FROM cars WHERE id = $id) as distance");
$builder->with(['transmissionType', 'drivenWheel', 'marketCategory', 'vehicleSize', 'drivenWheel']);
$builder->where([
['car_mark_id', '<>', $car->car_mark_id],
['car_model_id', '<>', $car->car_model_id],
]);
return
$builder->orderBy("distance")->paginate($count);
Результат возвращается с нужными полями и отношениями отсортированный в порядке убывания сходства. Исходный код проекта доступен по ссылке.
Использование эмбеддингов открывает множество возможностей для разработчиков в плане поиска сходства. В статье рассмотрели, как создать и выполнить поиск похожих товаров (автомобилей) через создание эмбеддиногов и характеристик. Кроме рассмотренного способа с использованием нормализации, можно использовать языковые модели. Помимо эмбеддинга для слов, характеристик можно также расчитывать эмбеддинги для изображений и аудио и также производить поиск.
Полезные ссылки:
https://github.com/pgvector/pgvector
https://weaviate.io/blog/distance-metrics-in-vector-search



